What is CHISQ.DIST.RT function in Excel?
The CHISQ.DIST.RT function is one of the Statistical functions of Excel.
It returns the right-tailed probability of the chi-squared distribution.
We can find this function in Statistical category of insert function Tab.
How to use CHISQ.DIST.RT function in excel
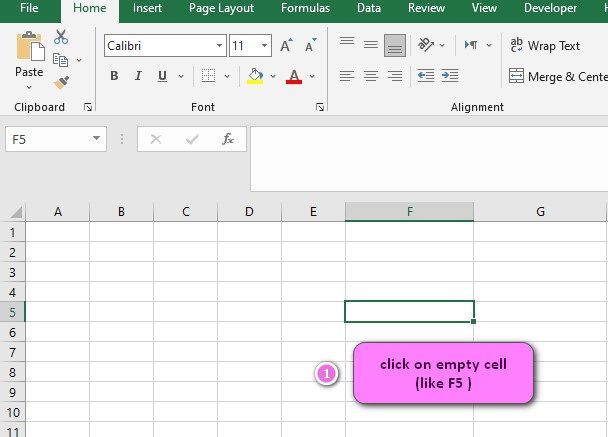
- Click on an empty cell (like F5).
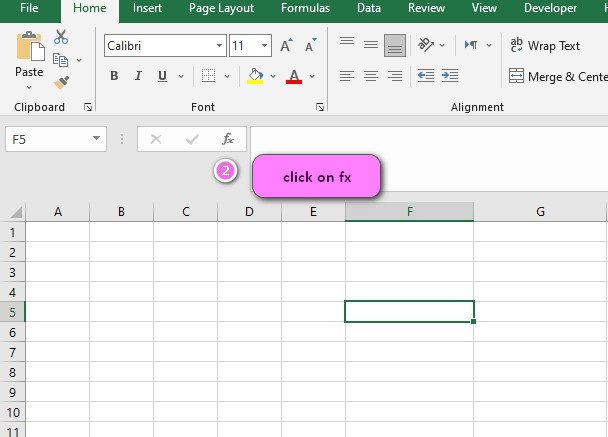
2. Click on the fx icon (or press shift+F3).
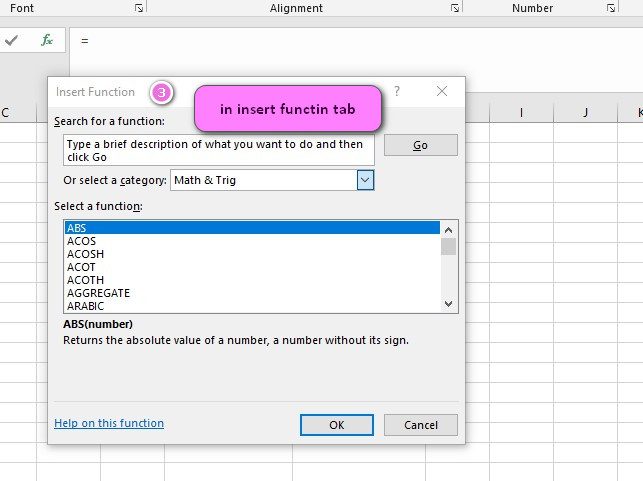
3. In the insert function tab you will see all functions.
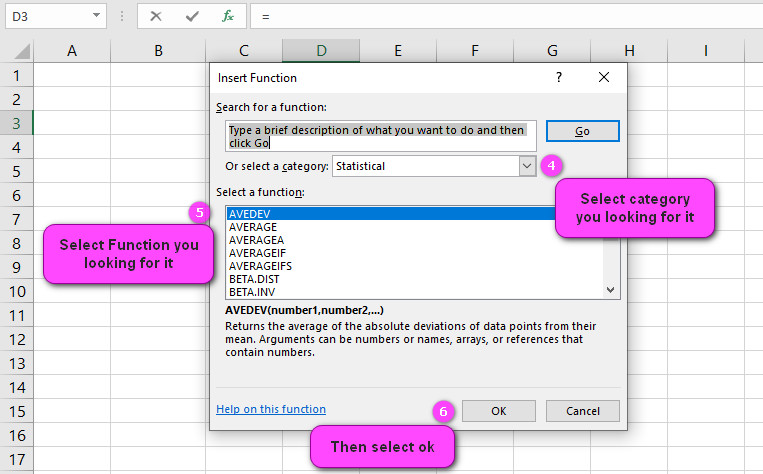
4. Select STATISTICAL category.
5. Select CHISQ.DIST.RT function.
6. Then select ok.
7. In the function arguments Tab you will see CHISQ.DIST.RT function.
8. X is the value at which you want to evaluate the distribution, a non-negative number.
9. Deg_freedom is the number of degrees of freedom, a number between 1 and 10^10, excluding 10^10.
10. You will see the results in the formula result section.
Examples of CHISQ.DIST.RT function in Excel
- To calculate the right-tailed probability of a chi-square statistic of 5 with 3 degrees of freedom, use the following formula: =CHISQ.DIST.RT(5,3).
- To calculate the right-tailed probability of a chi-square statistic of 10 with 4 degrees of freedom, use the following formula: =CHISQ.DIST.RT(10,4).
- To calculate the probability that a chi-square statistic is greater than or equal to 20, given 5 degrees of freedom, use the following formula: =CHISQ.DIST.RT(20,5).
- To calculate the probability that a chi-square statistic is greater than or equal to 15, given 7 degrees of freedom, use the following formula: =CHISQ.DIST.RT(15,7).
- To calculate the right-tailed probability of a chi-square statistic of 8, given 6 degrees of freedom, use the following formula: =CHISQ.DIST.RT(8,6).
- To calculate the probability that a chi-square statistic is greater than or equal to 12, given 9 degrees of freedom, use the following formula: =CHISQ.DIST.RT(12,9).
- To calculate the right-tailed probability of a chi-square statistic of 3, given 2 degrees of freedom, use the following formula: =CHISQ.DIST.RT(3,2).
- To calculate the probability that a chi-square statistic is greater than or equal to 25, given 8 degrees of freedom, use the following formula: =CHISQ.DIST.RT(25,8).
- To calculate the right-tailed probability of a chi-square statistic of 18, given 10 degrees of freedom, use the following formula: =CHISQ.DIST.RT(18,10).
- To calculate the probability that a chi-square statistic is greater than or equal to 30, given 12 degrees of freedom, use the following formula: =CHISQ.DIST.RT(30,12).
Excel’s CHISQ.DIST.RT Function: What You Need to Know
The CHISQ.DIST.RT function in Excel is a statistical function that calculates the right-tailed probability of the chi-square distribution. This function is commonly used in hypothesis testing, goodness-of-fit tests, and other statistical applications. In essence, the CHISQ.DIST.RT function tells you the probability of observing a value as extreme or more extreme than the test statistic, assuming that the null hypothesis is true.
How the CHISQ.DIST.RT Function Calculates Right-Tailed Probabilities in Excel
The CHISQ.DIST.RT function in Excel uses the chi-square distribution to calculate probabilities for the right-tailed test. The function takes two input arguments: the chi-square statistic and the degrees of freedom. The output of the function is the probability that a chi-square statistic with the given degrees of freedom is greater than or equal to the specified value.
For example, suppose we want to calculate the probability that a chi-square statistic with 5 degrees of freedom is greater than or equal to 10. We can use the following formula in Excel: =CHISQ.DIST.RT(10,5). The result is approximately 0.077, which means that there is only a 7.7% chance of observing a chi-square statistic of 10 or higher, assuming that the null hypothesis is true.
Input Arguments for Excel’s CHISQ.DIST.RT Function: A Guide
The CHISQ.DIST.RT function in Excel requires two input arguments: the chi-square statistic and the degrees of freedom. The chi-square statistic represents the test statistic for which we want to calculate the probability. The degrees of freedom represent the number of independent variables in the analysis minus one.
For example, suppose we have a contingency table that compares the relationship between age and smoking status. We calculate the chi-square statistic for this analysis and obtain a value of 15. The table has two independent variables (age and smoking status), so the degrees of freedom would be (2-1)*(2-1)=1. To calculate the right-tailed probability for this test statistic, we can use the following formula in Excel: =CHISQ.DIST.RT(15,1).
Understanding the Difference Between CHISQ.DIST and CHISQ.DIST.RT Functions in Excel
The CHISQ.DIST and CHISQ.DIST.RT functions in Excel are both used to calculate probabilities for the chi-square distribution. However, there is a key difference between the two functions: CHISQ.DIST calculates the cumulative probability up to a certain value, while CHISQ.DIST.RT calculates the probability beyond a certain value.
For example, suppose we want to calculate the probability that a chi-square statistic with 3 degrees of freedom is less than or equal to 5. We can use the following formula in Excel: =CHISQ.DIST(5,3). The result is approximately 0.321, which means that there is a 32.1% chance of observing a chi-square statistic of 5 or lower, assuming that the null hypothesis is true.
On the other hand, if we want to calculate the probability that a chi-square statistic with 3 degrees of freedom is greater than or equal to 5, we can use the following formula in Excel: =CHISQ.DIST.RT(5,3). The result is approximately 0.364, which means that there is a 36.4% chance of observing a chi-square statistic of 5 or higher, assuming that the null hypothesis is true.
Using the CHISQ.DIST.RT Function in Excel for Testing Independence in Contingency Tables
The CHISQ.DIST.RT function in Excel is commonly used to perform tests of independence in contingency tables. A contingency table is a type of frequency distribution table that displays the relationship between two or more categorical variables. The CHISQ.DIST.RT function can be used to test whether there is a significant association between these variables.
For example, suppose we have a contingency table that compares the relationship between age and income level. We calculate the chi-square statistic for this analysis and obtain a value of 10. The table has two independent variables (age and income level), so the degrees of freedom would be (3-1)*(2-1)=2. To test for independence using a significance level of 0.05, we can use the following formula in Excel: =IF(CHISQ.DIST.RT(10,2)<0.05,”Reject null hypothesis”,”Fail to reject null hypothesis”). If the p-value is less than 0.05, we would reject the null hypothesis and conclude that there is evidence for an association between age and income level in our sample.
The Significance Level Used in Excel’s CHISQ.DIST.RT Function Explained
The significance level used in Excel’s CHISQ.DIST.RT function is a value that determines the probability of rejecting the null hypothesis when it is actually true. It is also known as the alpha level.
For example, suppose we want to test if there is an association between two categorical variables – gender and smoking status. We can set the alpha level at 0.05. If the p-value from the chi-square test is less than 0.05, we reject the null hypothesis and conclude that there is sufficient evidence to support the alternative hypothesis, which is that there is an association between gender and smoking status.
Handling Missing Data and Outliers with Excel’s CHISQ.DIST.RT Function
Missing data and outliers can affect the accuracy of results obtained using Excel’s CHISQ.DIST.RT function in the chi-square test. There are several ways to handle missing data and outliers, such as:
- Imputation: In this method, missing values are replaced with estimated values based on other available information. There are several imputation techniques such as mean imputation, regression imputation, and multiple imputation.
- Removal of outliers: In this method, extreme or influential observations are removed from the dataset. This can be done by examining boxplots, histograms, or scatter plots.
For example, suppose we have a dataset consisting of students’ exam scores on different subjects. Some students’ scores are missing due to various reasons such as absenteeism or technical difficulties during the exam. We can use a multiple imputation technique to replace the missing scores with estimated values based on other available variables such as age, gender, and previous exam scores.
Accuracy of Probability Estimates from Excel’s CHISQ.DIST.RT Function: What to Expect
Excel’s CHISQ.DIST.RT function estimates the probability of obtaining a chi-square statistic at least as extreme as the observed value from a chi-square distribution under the null hypothesis. The accuracy of this estimate depends on various factors such as sample size, significance level, and expected cell frequencies.
For example, suppose we want to test if there is an association between two categorical variables – type of crime committed (robbery or theft) and age group (below 30 years or above 30 years). We can set the significance level at 0.05. If the p-value obtained from the chi-square test is less than 0.05, we reject the null hypothesis and conclude there is an association between the two variables. However, the accuracy of this conclusion depends on the sample size, the number of expected cell frequencies, and the chosen significance level.
Limits to Degrees of Freedom in Excel’s CHISQ.DIST.RT Function
Excel’s CHISQ.DIST.RT function has a limit on the degrees of freedom that can be used in the chi-square test. Specifically, it can handle up to 10^10 degrees of freedom.
For example, suppose we are testing the hypothesis that the proportions of males and females in a population are equal using a large sample size of 100,000. The degrees of freedom for this test would be 1, and it falls well within the limits of Excel’s CHISQ.DIST.RT function.
Interpreting Results from Excel’s CHISQ.DIST.RT Function: Tips and Best Practices
Interpreting results from Excel’s CHISQ.DIST.RT function involves understanding the statistical significance and practical significance of the findings. Some tips and best practices to keep in mind when interpreting these results include:
- Checking the assumptions of the chi-square test such as independence of observations and expected cell frequencies greater than 5.
- Examining the p-value and comparing it to the chosen significance level to accept or reject the null hypothesis.
- Calculating effect size measures such as Cramer’s V or phi coefficient to estimate the strength of the relationship between variables.
- Assessing the practical significance of the findings by considering if they have real-world implications.
For example, suppose we conducted a chi-square test to investigate the association between smoking status and lung cancer in a sample of 500 participants. The p-value obtained is less than 0.05, indicating a significant association. We also calculate the effect size measure, which shows a moderate positive relationship between smoking status and lung cancer. However, we can only conclude that there is an association between these two variables and not that smoking causes lung cancer.
Chi-Square Distribution vs Normal Distribution in Excel: Understanding the Relationship
The chi-square distribution and normal distribution are two types of probability distributions used in statistical analysis. While the normal distribution is continuous, the chi-square distribution is a discrete distribution that arises in the context of the chi-square test.
For example, suppose we have a dataset consisting of exam scores for 100 students. We can use the normal distribution to model the distribution of scores if the sample size is large enough, say n > 30. However, if we want to test if the distribution of scores follows a specific pattern such as a uniform distribution, we use the chi-square distribution with degrees of freedom equal to n-1.
Applying Excel’s CHISQ.DIST.RT Function to Test Goodness of Fit
Goodness of fit tests are used to determine if a sample data set fits a theoretical probability distribution. In Excel, we can use the CHISQ.DIST.RT function to test goodness of fit by calculating the chi-square statistic and obtaining the corresponding p-value.
For example, suppose we want to test if the observed frequencies of blood types in a sample of 500 individuals match the expected frequencies based on the Hardy-Weinberg equilibrium. We can use the CHISQ.DIST.RT function to calculate the chi-square statistic and obtain the p-value. If the p-value is less than the chosen significance level, we reject the null hypothesis and conclude that the observed frequencies do not follow the Hardy-Weinberg equilibrium.
Using Non-Numeric Data with Excel’s CHISQ.DIST.RT Function
Excel’s CHISQ.DIST.RT function requires numeric data for the calculation of the chi-square statistic. However, we can still use it to test hypotheses involving non-numeric data such as categorical variables.
For example, suppose we want to test if there is an association between favorite color and political affiliation in a sample of 1000 individuals. We can create a contingency table with the observed frequencies and use the CHISQ.DIST.RT function to obtain the chi-square statistic and corresponding p-value. If the p-value is less than the chosen significance level, we reject the null hypothesis and conclude that there is an association between favorite color and political affiliation.
Troubleshooting Errors in Excel’s CHISQ.DIST.RT Function: Solutions and Tips
Errors can occur in Excel’s CHISQ.DIST.RT function due to several reasons such as incorrect input values or assumptions violations. Some solutions and tips for troubleshooting errors include:
- Checking the input values: Ensure that all the input values are correct and in the appropriate format.
- Checking the range of expected cell frequencies: Verify that the expected cell frequencies are greater than or equal to 5.
- Checking for independence of observations: Ensure that the observations are independent and not correlated.
- Checking for outliers: Remove any outliers or influential observations from the data set.
Alternatives to Excel’s CHISQ.DIST.RT Function for Analyzing Chi-Square Distributions
While Excel’s CHISQ.DIST.RT function is a useful tool for analyzing chi-square distributions, there are other software packages that offer more advanced features and functionalities. Some popular alternatives include:
- R: A free and open-source programming language that offers powerful statistical analysis and visualization tools.
- SPSS: A commercial software package that offers comprehensive statistical analysis capabilities including chi-square tests.
- SAS: A commercial software package widely used in the healthcare industry for statistical analysis and modeling.
For example, suppose we want to conduct a power analysis for a chi-square test with a large sample size. We can use the R programming language to calculate the required sample size to achieve a specified power level and significance level.
Comparing Two Samples with Excel’s CHISQ.DIST.RT Function: How to Do It
Excel’s CHISQ.DIST.RT function can be used to compare two independent samples of categorical data. To do this, we can create a contingency table with the observed frequencies for each sample and use the function to calculate the chi-square statistic and p-value.
For example, suppose we want to test if there is an association between smoking status and lung cancer in two different populations – smokers and non-smokers. We can create a contingency table with the observed frequencies for each population and use the CHISQ.DIST.RT function to calculate the chi-square statistic and corresponding p-value. If the p-value is less than the chosen significance level, we reject the null hypothesis and conclude that there is an association between smoking status and lung cancer in both populations.
Choosing the Appropriate Degrees of Freedom for Your Analysis in Excel’s CHISQ.DIST.RT Function
The degrees of freedom (df) parameter in Excel’s CHISQ.DIST.RT function determines the number of parameters estimated from the sample data. The appropriate df value depends on the specific analysis being conducted and the number of variables involved.
For example, when analyzing a contingency table with r rows and c columns, the df value is equal to (r-1)*(c-1). In contrast, when conducting a test of independence between two categorical variables, the df value is equal to (number of rows -1) * (number of columns – 1).
Common Mistakes to Avoid When Using Excel’s CHISQ.DIST.RT Function
Some common mistakes to avoid when using Excel’s CHISQ.DIST.RT function include:
- Incorrect input values: Ensure that all the input values are correct and in the appropriate format.
- Violations of assumptions: Verify that the assumptions of the chi-square test such as independence of observations and expected cell frequencies greater than 5 are met.
- Choosing an inappropriate significance level: Choose a significance level that is appropriate for the specific analysis being conducted.
- Using an incorrect degrees of freedom value: Ensure that the df value used in the function is appropriate for the specific analysis.
Real-World Applications of Excel’s CHISQ.DIST.RT Function: Examples and Use Cases
Excel’s CHISQ.DIST.RT function has various real-world applications in fields such as healthcare, finance, and marketing. Some examples and use cases include:
- Healthcare: Analyzing the association between smoking status and lung cancer incidence in a population.
- Finance: Testing if stock prices follow a specific distribution such as the normal distribution or the log-normal distribution.
- Marketing: Investigating the association between product features and customer preferences in a survey.
Where to Find Additional Resources for Learning About Excel’s CHISQ.DIST.RT Function
There are numerous resources available for learning more about Excel’s CHISQ.DIST.RT function, including tutorials, online courses, and textbooks. Some popular resources include:
- Microsoft Office support website: Offers free tutorials and guides on how to use Excel’s CHISQ.DIST.RT function.
- Online courses: Websites such as Coursera, Udemy, and edX offer online courses on statistics and data analysis that cover the usage of Excel’s CHISQ.DIST.RT function.
- Textbooks: There are several textbooks on statistics and data analysis that cover the usage of Excel’s CHISQ.DIST.RT function, such as “Statistics for Business and Economics” by Anderson, Sweeney, and Williams.
CHISQ.DIST.RT related functions
- Use CHISQ.DIST function to return the left-tailed probability of the chi-squared distribution.
- Use CHISQ.INV function to return the inverse of the left-tailed probability of the chi-squared distribution.
- Use CHISQ.INV.RT function to return the inverse of the right-tailed probability of the chi-squared distribution.
- Use CHISQ.TEST function to return the test for independence.
